Tudo que você precisa saber sobre SQL

I'm currently working as a Senior Data Engineer (job 1) and as a Solutions Architect & Backend developer (job 2, freelancer). I'm a certified Google Cloud Professional Data Engineer and I really like talking about new technologies. My main focus are:
- Help people get started
- Talk about new tools and how we should be using them instead of developing everything ourselves
SQL é uma linguagem de manipulação e consulta de dados, que é usada em diversas ferramentas diferentes e que nos permite interagir com os bancos de dados sem a necessidade de muitos conhecimentos em linguagem de programação. Hoje a linguagem é um requisito chave em todas as carreiras da área de dados, mas também é um conhecimento muito importante para pessoas desenvolvedoras de backend.
Pra ser sincero, esse assunto é super relativo e as suas necessidades podem variar de acordo com o tipo de trabalho que vai fazer. Vou descrever algumas coisas intermediárias e focar em boas práticas de escrita de consultas, que acredito ser o mais importante. A partir do entendimento básico, a habilidade mais importante passa a ser conseguir usar as documentações da linguagem e das ferramentas para conseguir fazer o que você precisar.
Tudo que eu preciso saber sobre?
Meu objetivo aqui é simples: prover toda informação disponível para você (desenvolvedor) começar e conseguir usar a ferramenta da vez. Não pretendo responder tudo que você pode ou deveria saber, apenas o necessário.
O que é SQL
SQL é a sigla para Structured Query Language, ou em tradução livre, Linguagem de consulta estruturada. Isso ajuda a entender o principal objetivo, que é consultar dados. Apesar disso, é possível fazer muito mais coisas utilizando SQL.
De forma mais geral, SQL é usada para consultar e manipular dados em bancos de dados relacionais, além de gerenciar e manter as estruturas de dados (como tabelas, por exemplo).
É uma linguagem declarativa, o que significa que você descreve quais são os resultados que você espera, e não exatamente como o computador deve calcular ou retornar eles.
Variantes de SQL
Existem vários “dialetos” diferentes de SQL, que aproveitaram o padrão e estenderam suas funcionalidades de acordo com o ponto de vista de algumas empresas específicas. A maior parte da sintaxe é compartilhada, e a não ser que você queira trabalhar como pessoa administradora de banco de dados de uma empresa que usa várias ferramentas distintas, você provavelmente não precisa aprender todas. Mas é importante entender que se pegarmos os principais bancos de dados do mercado (Microsoft SQL Server, PostgreSQL, MySQL, Oracle), cada um vai ter funções e pedaços de sintaxe levemente diferente dos outros.
Quando eu deveria usar SQL
Bom, se você estiver usando um banco de dados relacional, provavelmente vai precisar usar SQL. Mesmo que você esteja usando uma biblioteca intermediária na sua linguagem (geralmente são chamadas de ORM, e permitem a utilização do banco de dados quase sem depender de SQL. Sequelize em NodeJS e SQLAlchemy em python são alguns exemplos), nem toda manipulação é traduzida para a biblioteca.
Nós poderíamos ir um passo atrás e questionar quando deveria usar um banco de dados relacional, visto que existem diversos tipos diferentes de bancos de dados, mas é um assunto extenso e pretendo falar sobre todos eles no futuro.
Ou seja, a utilização de SQL provavelmente vem da definição da ferramenta que está sendo utilizada no seu time.
E apenas para encerrar esse tópico, queria ressaltar que é possível usar SQL (ou algo muito parecido) em ferramentas que não foram feitas para isso. Dentro do framework Spark, de processamento de dados, você pode escolher usar SQL ao invés da API de dataframes na linguagem usada (geralmente python, por ex). E o meu exemplo preferido, é possível usar um “pseudo-SQL” em planilhas do Google para consultar seus dados. Também vou escrever sobre isso em breve.
Por onde começar
Por ser uma linguagem declarativa, a melhor forma de aprender é na prática. Por isso, na minha opinião, para começar é importante conseguir um local para executar suas consultas. Então vou trazer 4 opções:
SQL Bolt

O SQL Bolt é um bom começo, apesar de limitado. Além de ter conteúdo sobre a sintaxe, ele oferece alguns problemas simples para ser resolvidos, de forma que você não precisa se preocupar em configurar um banco de dados.
DB Fiddle

O db fiddle é um ótimo jeito de praticar SQL em geral, mas ele não tem tabelas prontas para você utilizar. Testei usar o Chat GPT e pedir para ele descrever tabelas e exercícios, e ele conseguiu atender bem a necessidade. Você pode descrever quais tabelas quer, quais campos cada uma deve ter e pedir que ele gere o SQL para criar as tabelas e preenchê-las com dados.
BigQuery

Quem me conhece sabe que é uma das minhas ferramentas preferidas, porque é possível fazer muita coisa com ele. O BigQuery é a ferramenta de Data Warehouse da Google Cloud, e além de oferecer uma cota gratuita (1 tb de dados processados, 10 gb de dados armazenados), ele também conta com uma série de datasets públicos que podem ser utilizados para estudos. Lá encontramos dados de github, da wikipedia, dados de tráfego aéreo e taxis dos EUA e mais uma dezena de coisas diferentes.
PostgreSQL + pgAdmin + Docker
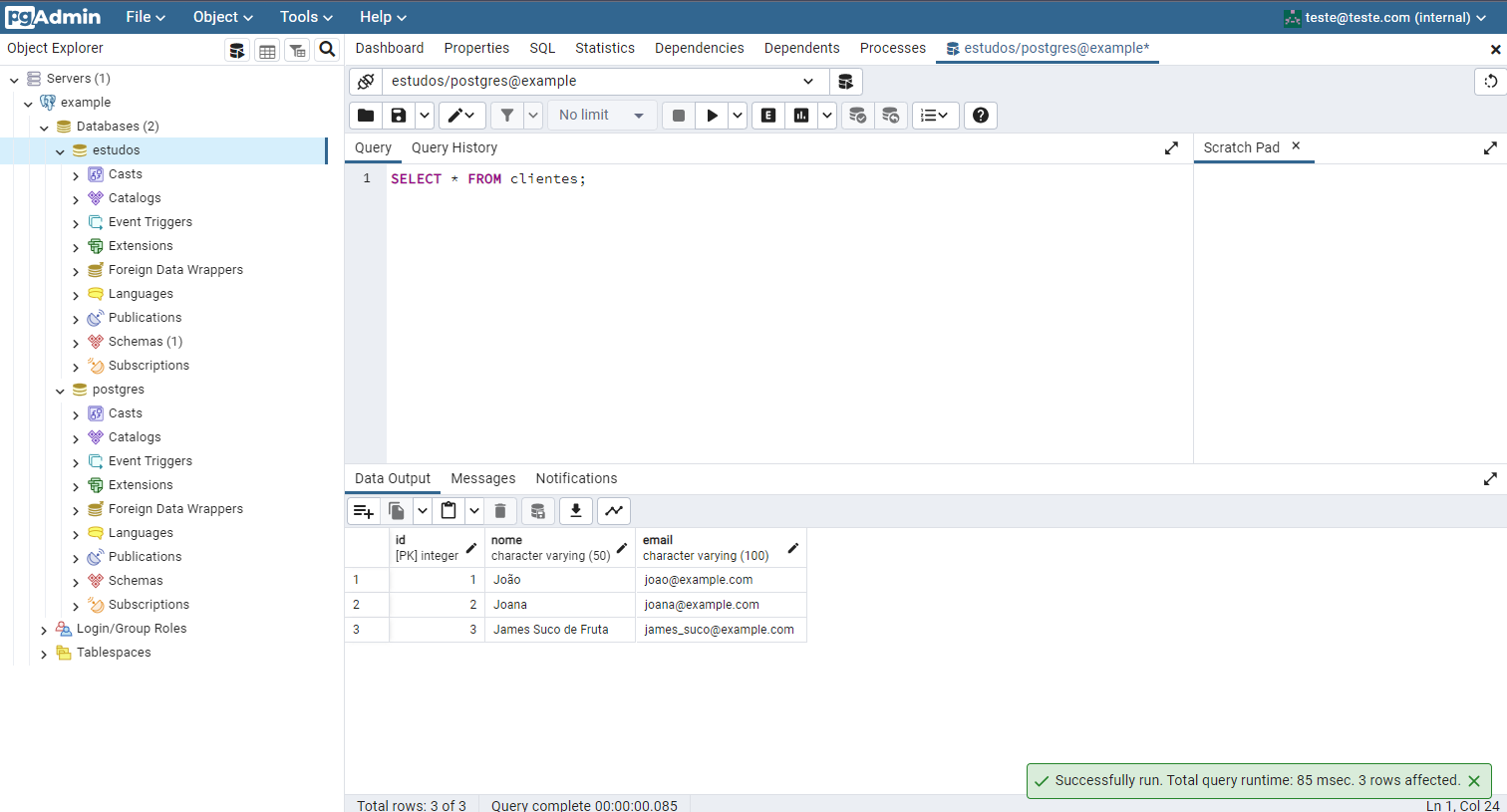
Um dos motivos de ter feito o post sobre Docker tão cedo, é que ele passa a ser requisito para facilitar nossa vida e nossos estudos.
Nesse repositório do github deixei os arquivos e uma explicação de como utilizar.
Para usar, você só precisa de um docker-compose.yml
# docker-compose.yml
version: '3.8'
services:
postgres:
image: postgres:15
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=password
volumes:
- postgres-db-volume:/var/lib/postgresql/data
ports:
- 5432:5432
networks:
- postgres-db-network
pgadmin:
image: dpage/pgadmin4
environment:
PGADMIN_DEFAULT_EMAIL: 'teste@teste.com'
PGADMIN_DEFAULT_PASSWORD: 'teste'
ports:
- 16543:80
volumes:
- ./servers.json:/pgadmin4/servers.json
networks:
- postgres-db-network
volumes:
postgres-db-volume:
driver: local
driver_opts:
type: none
o: bind
device: ./data
networks:
postgres-db-network:
driver: bridge
E nesse exemplo, criei o arquivo servers.json para que você não precise fazer a configuração na interface:
{
"Servers": {
"1": {
"Name": "example",
"Group": "Servers",
"Host": "postgres",
"Port": 5432,
"MaintenanceDB": "postgres",
"Username": "postgres",
"PassFile": "/pgpass",
"SSLMode": "prefer"
}
}
}
Depois, basta executar o comando docker compose up no diretório. Isso vai criar 2 contêineres: um responsável pelo banco de dados, e que está disponível na porta 5432 (Ele também tem um volume montado na pasta data . Isso é um bônus caso você queira que os seus dados persistam no disco, e não só no volume do docker). E um container com o pgdamin, que é uma ferramenta open source de utilização do postgres.
Então basta acessar o endereço localhost:16543 no seu navegador, fazer login no pgadmin, e abrir a opção Servers no menu da esquerda. Um popup pedindo a senha do banco de dados deve aparecer, basta preencher e confirmar.
Com esse setup, você deve conseguir fazer qualquer curso de bancos de dados sem grandes problemas.
A linguagem
Antes de continuar, precisamos esclarecer uma coisa. SQL pode ser dividido em 5 pedaços:
DDL - Data Definition Language, ou Linguagem de Definição de Dados. São os comandos para gerenciar os objetos do banco de dados.
DML - Data Manipulation Language, ou Linguagem de Manipulação de Dados. São os comandos que gerenciam os dados dentro das tabelas.
DQL - Data Query Language, ou Linguagem de Consulta de Dados. São os comandos para consultar os dados.
DTL - Data Transaction Language, ou Linguagem de Transação de Dados. São comandos específicos para controlar transações, que não é um assunto que vou tratar hoje.
DCL - Data Control Language - Linguagem de Controle de Dados. São os comandos que controlam os acessos ao banco de dados e seus recursos. Também não vamos falar sobre isso.
Essas divisões podem ser diferentes em alguns materiais (alguns livros consideram o SELECT como DML e não como uma etapa completamente separada, o DQL). E algumas ferramentas não tem todas essas etapas. Então daqui pra frente, vamos falar brevemente de DDL e DML dando um resumo e exemplo dos principais comandos de cada um. No final vamos detalhar DQL, que vai ser a parte mais extensa.
E outra coisa importante: normalmente escrevemos as palavras chave de SQL em maiúsculo. Isso não é obrigatório, mas ajuda a separar o que é palavra reservada do que não é. Então daqui pra frente, toda palavra em maiúsculo você pode considerar como palavra especial ou função
DDL
CREATE
O comando CREATE é usado para criar objetos de banco de dados, como tabelas ou views, por exemplo.
Para criar uma tabela, precisamos descrever todas as suas colunas, os seus tipos e mais algumas regras (por ex, se aquele campo pode ser vazio ou não). No exemplo abaixo criamos uma tabela “clientes”, com os campos id, nome e email. Lembrando que como estou usando o postgresql, temos algumas coisas especificas, como o tipo SERIAL no id abaixo.
CREATE TABLE clientes (
id SERIAL PRIMARY KEY,
nome VARCHAR(50),
email VARCHAR(100)
);
Também podemos criar views, que são uma forma de armazenar consultas prontas no nosso banco de dados. Para isso, a sintaxe é como abaixo:
CREATE VIEW consulta_clientes AS
SELECT nome FROM clientes;
DROP
O comando DROP é usado para excluir objetos de banco de dados, como as tabelas. Veja que não estamos falando de apagar os dados, mas a tabela em si.
DROP TABLE clientes;
ALTER
O comando ALTER é usado para modificar a estrutura de objetos de banco de dados já existentes, como adicionar ou remover colunas de uma tabela.
ALTER TABLE clientes
ADD telefone VARCHAR(20);
TRUNCATE
O comando TRUNCATE é usado para remover todos os dados de uma tabela, mas mantendo a estrutura da tabela.
TRUNCATE TABLE clientes;
DML
INSERT
O comando INSERT é usado para adicionar novos registros a uma tabela.
INSERT INTO clientes (nome, email)
VALUES ('João', 'joao@example.com');
É interessante notar que podemos inserir mais de uma linha de uma vez:
INSERT INTO clientes (nome, email)
VALUES ('Joana', 'joana@example.com'),
('James', 'james@example.com');
E também podemos inserir numa tabela o resultado de uma consulta. Por exemplo, se tivermos uma tabela clientes_backup
INSERT INTO clientes (SELECT id, nome, email FROM clientes_backup);
UPDATE
O comando UPDATE é usado para modificar os registros existentes em uma tabela. Tanto para o UPDATE quanto para o DELETE, é muito importante filtrar em quais dados estaremos mexendo, pois esses comandos podem alterar todos os dados da tabela se usados sem cuidado. A sintaxe do update é a seguinte:
UPDATE clientes
SET nome='James Suco de Fruta', email='james_suco@example.com'
WHERE email='james@example.com'
Veja que agora temos a palavra chave SET, que é usada para escolher quais colunas iremos alterar e quais serão os novos valores. Aproveitei para deixar no exemplo a alteração de duas colunas, para mostrar como fica a sintaxe.
Além disso, aqui vemos pela primeira vez a utilização do WHERE, que é a forma de filtrar dados no SQL. O legal do SQL é que tendo um conhecimento básico de inglês, conseguimos entender exatamente o que está sendo feito. Vou detalhar melhor as condições de WHERE quando falarmos de SELECT, então por hora isso é tudo.
DELETE
O comando DELETE é usado para remover registros de uma tabela. E ressaltando mais uma vez, é extremamente importante filtrar os dados quando for utilizar esse comando. Um delete sem WHERE é equivalente a apagar todos os dados da tabela.
DELETE FROM clientes
WHERE id = 5;
DQL
A princípio, o DQL tem somente um comando: SELECT. Mas vamos aproveitar esse pedaço para falar sobre a estrutura de uma consulta e das funções disponíveis.
Sintaxe básica
SELECT
nome AS nome_cliente
FROM
clientes
WHERE
sexo="m"
ORDER BY id
LIMIT 2
SELECT
É usado para selecionar os dados (é). Os dados são retornados num formato tabelar. Aqui você pode descrever quais são as colunas que quer selecionar, pode acrescentar colunas novas no resultado, utilizar condicionais e agregações (descritos mais abaixo), dar novos nomes às colunas. A sintaxe é simples e a melhor forma de entender é testando, então recomendo novamente dar uma olhada no SQL bolt.
De forma geral:
*vai retornar todas as colunascolunavai retornar uma coluna com o mesmo nome.coluna AS apelido_colunavai mudar o nome da coluna somente no resultadoDISTINCTpode ser usado para trazer uma combinação de valores distintos das suas colunas* EXCEPT(coluna_2, coluna_3)pode ser utilizado para retornar todas as colunas menos algumas específicas.
FROM
Aqui definimos de onde vamos consultar. A forma como o endereço é passado depende da ferramenta de banco de dados, no caso do postgres você pode passar somente o nome da tabela (caso esteja usando o schema public, que é o padrão), ou o formato schema.tabela . Os JOIN (que estão descritos mais abaixo) também fazem parte do FROM, pois são uma forma de acrescentar mais tabelas no resultado.
WHERE
Usamos o WHERE para filtrar os resultados com base numa condição pré-definida. Para isso precisamos saber os operadores condicionais básicos:
>(maior):altura>150<(menor):idade<25=(igual):email='cadu@cadumagalhaes.dev'!=ou<>(diferente):nome!='Cadu'>=(maior ou igual):idade>=18<=(menor ou igual):sapato<=40BETWEEN(entre):idade BETWEEN 18 AND 25IN ()(valor pertence a lista):cidade IN ('SP','RJ')LIKEdetalhes abaixo
E os operadores lógicos:
AND:idade>12 AND cidade='Sao Paulo'OR:cidade='Sao Paulo' OR cidade='Rio de Janeiro'
LIKE
O LIKE tem uma estrutura diferente e por isso achei melhor deixar separado. A principio, ele pode ser usado como o =:
WHERE nome LIKE 'Carlos'
E nesse caso, vai trazer somente caso o resultado seja exatamente igual. Mas o like tem 2 operadores:
%: pode ser substituido por qualquer coisa em qualquer quantidade_: pode ser substituido por uma ocorrência de qualquer coisa
Por exemplo, caso queiramos saber todos os nomes que começam com Carlos, fazemos assim:
WHERE nome LIKE 'Carlos%'
Nesse caso, eu leio como “Carlos qualquer coisa”, porque é o que ele vai retornar. Se for somente Carlos, retorna. Se tiver outras coisas, como “Carlos Eduardo”, também retorna. O valor “Roberto Carlos” não seria retornado nesse caso, pois não começa com nossa condição.
Se quisermos saber todos os nomes que terminam com Silva, fazemos assim:
WHERE nome LIKE '%Silva'
De forma semelhante, não importa o que há antes, desde que termine com Silva.
Se quisermos saber todos os nomes que contém Carlos, fica assim:
WHERE nome LIKE '%Carlos%'
Note que agora colocamos o símbolo de porcentagem antes e depois do texto que estamos buscando.
Para entender o outro operador, vamos imaginar que temos uma coluna que tem as iniciais dos nomes das pessoas. Temos o Cadu Magalhães (CM), o Cristiano Ronaldo (CR7), o Ronaldo Fenômeno (R9), o Roberto Carlos (RC) e o Neymar (NJR)
Se por algum motivo nós quisermos somente os resultados em que o R seja a segunda letra, a nossa consulta ficaria assim:
WHERE iniciais LIKE '_R%'
Dessa forma, estamos limitando que só pode haver um caractere antes do que estamos procurando. Honestamente nunca precisei usar esse operador, mas pouca gente fala sobre isso então achei legal trazer.
ORDER BY
Usado para definir a ordenação dos resultados em ordem ascendente ou descendente, com base em uma ou mais colunas.
ORDER BY idade
#ou
ORDER BY idade, genero, cidade DESC
Por padrão, vai ordenar de forma ascendente. Mas podemos especificar passando ASC ou DESC.
LIMIT
Usado para definir a quantidade de resultados que deve ser retornada. Por ex, para saber o top 3 de uma competição:
SELECT nome
FROM resultados
ORDER BY nota
LIMIT 3
OFFSET
Geralmente é usado junto com o LIMIT quando precisamos retornar algum número que não esta exatamente no topo. Serve para dizer quantas linhas do inicio devem ser puladas antes de retornar. Por exemplo, se eu quiser uma consulta que retorne somente o segundo colocado da competição:
SELECT nome
FROM resultados
ORDER BY nota
LIMIT 1
OFFSET 1
UNION
UNION é usado para juntar tabelas de forma vertical, ou seja, empilhar uma em cima da outra. É uma forma de aumentar o número de linhas, e não de colunas.
Por exemplo, se temos 2 tabelas de clientes e queremos juntar o resultado:
SELECT * FROM clientes_1
UNION
SELECT * FROM clientes_2
Esse comando tem uma variação, que é o UNION ALL. A diferença é que por padrão, o UNION vai juntar somente resultados únicos. Então se uma mesma linha está nas duas tabelas, vai aparecer uma única vez. Quando usamos UNION ALL, todas as linhas são retornadas, incluindo duplicidades.
Joins
A partir daqui as coisas começam a ficar confusas de novo. Temos 5 tipos de join, e é bem difícil explicar as diferenças em texto. Join é uma forma de juntar duas tabelas horizontalmente. Ou seja, vamos colocar uma tabela do lado da outra, de acordo com uma condição pré definida. Para isso, vamos considerar sempre que a tabela que colocamos no nosso FROM está na esquerda, e a tabela que estamos dando JOIN está na direita. Isso vai facilitar o entendimento de algumas coisas.

INNER JOIN
Retorna somente as linhas em que a condição de join deu resultado nas tabelas dos dois lados.
LEFT JOIN
Retorna todas as linhas da tabela da esquerda, e preenche na direita somente o que deu resultado. Quando não houver match, vai preencher com null. É um bom jeito de acrescentar informações nas tabelas.
RIGHT JOIN
O contrário do LEFT JOIN, é só uma questão de referencial.
FULL OUTER JOIN
Retorna todas as linhas, não só as que deram match mas as que não deram também, dos dois lados.
CROSS JOIN
Vai juntar cada uma das linhas da primeira tabela com todas as linhas da segunda tabela. Ou seja, vai retornar um “produto cartesiano”* das duas tabelas.
A melhor forma de entender joins é com exemplos, e acho que esse é o tipo de coisa que fica muito mais confusa se for somente por texto. Se acharem necessário, posso revisar esse post e acrescentar exemplos para cada um deles, mas por enquanto vou economizar esses minutos de leitura (e possivelmente horas de escrita). Então comenta aqui no post se quiser que eu tente explicar melhor os joins :)
Funções de agregação
COUNT
Serve para contar a quantidade de resultados com base na agregação definida. Por exemplo, se eu quiser saber quantas pessoas de cada gênero tem na minha tabela de clientes:
SELECT
genero,
COUNT(*) as total
FROM clientes
GROUP BY genero
Veja que no exemplo eu acrescentei o GROUP BY. Quando começamos a agregar os dados, precisamos garantir que as nossas dimensões também estejam agregadas. Se não agruparmos, o banco de dados retornará um erro por não saber o que fazer com a coluna de gênero.
Também podemos removê-la e contar o total de clientes:
SELECT
COUNT(*) as total
FROM clientes
E nesse caso não precisamos agrupar por outras colunas.
SUM
Serve para somar o valor de uma determinada coluna e retornar o total.
SELECT
cliente,
SUM(receita) AS receita_total
FROM
compras
GROUP BY clientes
Importante ressaltar que só pode somar valores numéricos.
AVG
Calcula o valor médio de uma coluna.
SELECT
cliente,
AVG(receita) AS receita_media
FROM
compras
GROUP BY clientes
MAX
Retorna o maior valor de uma coluna.
SELECT
cliente,
MAX(receita) AS maior_receita
FROM
compras
GROUP BY clientes
MIN
Retorna o menor valor de uma coluna.
SELECT
cliente,
MIN(receita) AS menor_receita
FROM
compras
GROUP BY clientes
GROUP BY
Bom, já falei ali atrás, mas o principal uso do GROUP BY é ajudar a retornar as funções de agregação junto de uma dimensão. Você também pode usar o GROUP BY pra deduplicar (literalmente agrupar) linhas nas colunas.
HAVING
Um detalhe importante aqui, é que nós não conseguimos usar WHERE para filtrar o resultado de agregações. Por exemplo, se eu quiser trazer somente os clientes cuja receita média é maior que 100, isso não pode ser feito no WHERE.
Para isso existe o HAVING, que permite que façamos filtros nos resultados com base nas agregações. E vou aproveitar para mostrar como usar tudo isso de uma vez:
SELECT
cliente,
SUM(receita) AS total_receita,
AVG(receita) AS media_receita,
COUNT(*) AS numero_pedidos
FROM
pedidos
LEFT JOIN clientes USING(cliente_id)
WHERE cidade='Sao Paulo'
GROUP BY cliente
HAVING numero_pedidos<10
ORDER BY total_receita
LIMIT 3
Essa consulta traz o top 3 clientes que mais gastaram em São Paulo e que fizeram menos de 10 pedidos, com o detalhe de que a informação da cidade não está disponível na tabela de pedidos.
Funções condicionais
Tecnicamente as condicionais também são funções de agregação
IF
Serve para definir o valor de uma coluna com base numa condição simples, com apenas 2 possíveis resultados.
IF(condicao, valor se true, valor se false) AS coluna
Exemplo:
IF(pais='BR', 'pessoa brasileira', 'pessoa estrangeira') AS nacionalidade
CASE
Serve para definir o valor de uma coluna com base em qualquer condição, com N possíveis resultados, além de um valor padrão caso nenhuma condição seja verdadeira.
CASE
WHEN condicao_1 THEN valor 1
WHEN condicao_2 THEN valor 2
ELSE valor default
END AS coluna
Exemplo:
CASE
WHEN pais='BR' THEN 'pessoa brasileira'
WHEN pais='EUA' THEN 'pessoa americana'
ELSE 'outros'
END AS nacionalidade
Funções de texto
LOWER
Transforma o valor de uma coluna em minúsculas.
LOWER(coluna) as coluna
UPPER
Transforma o valor de uma coluna em maiúsculas.
UPPER(coluna) as coluna
CONCAT
Concatena (junta) valores de texto em uma única coluna.
CONCAT(valor_1, 'string', valor_2) as coluna
Provavelmente existem outras centenas de funções, essas são as mais comuns para tratamentos simples de dados.
Subconsultas
Honestamente eu tenho muito receio com o conceito de subconsultas porque a leitura pode ficar bem ruim. Para quem conhece Javascript, isso me lembra um pouco o callback hell de quando não tinhamos async await. A ideia é que podemos executar pequenos SELECT’s em qualquer parte da nossa consulta. Por exemplo:
-- Consulta principal para encontrar pedidos que contenham um item específico
SELECT
numero_pedido,
data_pedido
FROM pedidos
WHERE numero_pedido IN (
-- Subconsulta para encontrar os números de pedido que contêm o item específico
SELECT numero_pedido
FROM itens_pedidos
WHERE nome_item = 'Produto X'
);
Primeiramente obrigado Chat GPT por me dar um exemplo. Segundamente, estamos fazendo uma consulta que retorna todos os pedidos que tiveram um determinado produto. Mas essa consulta poderia ser mais complexa. Imagine que não queremos somente os pedidos, queremos pegar nosso exemplo anterior e juntar também a cidade de onde cliente é:
-- Consulta principal para encontrar pedidos que contenham um item específico
SELECT
cidade,
data_pedido,
COUNT(numero_pedido) as total_pedidos,
SUM(receita_pedido) AS total_receita
FROM (
--Subconsulta para juntar a tabela de pedidos com a de clientes
SELECT
numero_pedido,
data_pedido,
receita_pedido,
cidade_cliente
FROM
pedidos
LEFT JOIN clientes USING(cliente_id)
)
WHERE numero_pedido IN (
-- Subconsulta para encontrar os números de pedido que contêm o item específico
SELECT numero_pedido
FROM itens_pedidos
WHERE nome_item = 'Produto X'
)
GROUP BY cidade, data_pedido
E acho que podemos ver como a dificuldade de leitura da consulta aumenta junto com a complexidade. Já precisei trabalhar com consultas legadas que tinham mais de 10 níveis de subconsulta atrás de subconsulta, num pesadelo de SELECT * FROM (SELECT * FROM (SELECT * FROM (SELECT * FROM... . Fora as limitações: as subconsultas só podem ser referenciadas uma vez. Se por algum motivo um outro pedaço da sua query precisar de uma subconsulta, você vai precisar repetir.
CTE’s
E é aí que entram as CTE’s, do inglês Common Table Expression,* ou Expressão de Tabela Comum. A CTE é uma construção que permite definir uma tabela temporária dentro da sua consulta. Tem exatamente a mesma ideia que a subconsulta, com a diferença de que a sintaxe fica um pouco mais clara, e de que ela pode ser referenciada várias vezes na sua consulta.
Minha recomendação é usar CTE sempre que possível no lugar de uma subconsulta.
Acho que o jeito mais fácil de explicar é refatorar o exemplo acima, então aqui vai:
WITH pedidos_com_produto AS (
-- Subconsulta para encontrar os números de pedido que contêm o item específico
SELECT numero_pedido
FROM itens_pedidos
WHERE nome_item = 'Produto X'
),
pedidos_e_cidades AS (
--Subconsulta para juntar a tabela de pedidos com a de clientes
SELECT
numero_pedido,
data_pedido,
receita_pedido,
cidade_cliente
FROM
pedidos
LEFT JOIN clientes USING(cliente_id)
)
-- Consulta principal para encontrar pedidos que contenham um item específico
SELECT
cidade,
data_pedido,
COUNT(numero_pedido) as total_pedidos,
SUM(receita_pedido) AS total_receita
FROM pedidos_e_cidades
WHERE numero_pedido IN pedidos_com_produto
GROUP BY cidade, data_pedido
Pode ser um grande preconceito meu, mas para mim, essa segunda consulta é muito mais legível. Caso a sintaxe não tenha ficado clara, definimos uma CTE usando:
WITH nome_tabela_temporária AS (
subconsulta
)
Além disso, separamos múltiplas CTE’s por vírgula. E no final, a nossa consulta precisa terminar com um SELECT.
Absolutamente toda consulta com mais de uma etapa que eu escrevo é feita com CTE’s, porque além de separar de forma declarativa as etapas, também ajuda a separar os passos durante a construção da consulta. Se puder deixar uma lição com esse post, é que você tente usar CTE’s caso vá fazer grandes consultas.
Ordem de operações do SELECT
Por padrão, o SQL executa cada cláusula da consulta em uma ordem bem determinada. É interessante entender essa ordem para saber como otimizar consultas, mas isso também nos ajuda a entender como as ferramentas interpretam nosso código.
FROM, incluindo JOINs
WHERE
GROUP BY
HAVING
WINDOW functions
SELECT
DISTINCT
UNION
ORDER BY
LIMIT e OFFSET
Note que o LIMIT é avaliado no final da consulta. Em alguns bancos de dados, isso significa que ele não vai limitar o custo de processamento da sua consulta, apenas o resultado mostrado. Então por via de regra, se você quer economizar em processamento, use o WHERE.
Outras coisas
Além disso tudo ainda existem outros milhares tipos de funções que não trouxe aqui. Podemos lidar com dados geográficos, funções estatísticas, matemáticas, de definição de data, de timestamp e mais um monte de coisas.
Além disso, não mencionei alguns outros assuntos um pouco mais avançados, como funções analíticas e de janelamento, subconsultas correlatas ou até a otimização de queries. Talvez eu faça um outro post sobre SQL avançado, mas não está no cronograma dos próximos meses.
Onde encontrar mais informações
Sinceramente, aprendi SQL na prática muitos anos atrás, fazendo sistemas de CRUD como todo desenvolvedor. Como já mencionei, as próprias documentações das ferramentas tem bons exemplos e explicações da sintaxe das funções, então quando preciso de algo, vou atrás delas.
Também gostei desse material aqui da Data Engineering Wiki, que é um resuminho simples de metade do que falei aqui e mais algumas coisas.
Sei que a Linux Tips fez algumas lives de “SQL Essentials”, que acompanhei brevemente e também recomendo:
E caso você queira usar o BigQuery, o Google tem uma documentação muito boa sobre o “GoogleSQL” que define toda a sintaxe, as expressões e as funções. Toda vez que quero fazer algo que não sei fazer no BigQuery, entro na documentação oficial e os exemplos sempre ajudam.
Vi por cima os materiais da W3Schools e acho que tem bons exemplos e explicações também.
Sobre bancos de dados, o @danielhe4rt tem uma série de 4 partes com alguns conceitos bem interessantes.
De forma geral eu aprendi SQL faz muito tempo e não sei boas referências atuais. Se você souber algum bom curso, vídeo, post ou qualquer material manda aí!
E como spoiler, estou há algum tempo planejando um curso completo de SQL, mas com foco em BigQuery. Não tenho nenhuma estimativa, mas com certeza vai sair.
Conclusão
Para mim, o mais importante para saber SQL é entender qual o resultado que você quer, e com base nisso se virar para pesquisar (ou perguntar ao Chat GPT) como você pode fazer.
Uma coisa que faço e que acho boa prática, é que quando vou explicar para alguém como fazer uma determinada tabela, eu construo um exemplo do resultado esperado numa planilha. Como trabalho com modelagem e tratamento de dados, isso também ajuda os analistas a entender como vai ser a tabela que eles vão receber para construir um dashboard ou fazer uma análise, e isso evita retrabalhos caso a nossa consulta não retorne o que precisam.
Também precisa ficar claro que SQL é o tipo de habilidade que você só vai desenvolver praticando. Por mais que você entenda uma consulta feita por alguém, isso não significa que você seria capaz de escrevê-la.
No início a prática consiste em nos acostumarmos com a sintaxe, mas conforme as necessidades vão se tornando mais complexas, ter praticado problemas semelhantes vai te ajudar muito. É difícil falar para uma pessoa iniciante que ela deve pensar por partes e ir desenvolvendo aos poucos, mas essa é a minha principal habilidade na resolução de problemas em geral.
Então minhas dicas são: tente desenhar qual é o resultado final que você quer, escreva de onde vai vir cada dado, e na hora de executar faça uma parte de cada vez, sempre tentando executar partes menores para garantir que está funcionando. Quem sabe a frustração de escrever uma consulta gigante que da erro ou retorna nada vai concordar comigo aqui.
E no geral, entenda bem o custo de executar as coisas na ferramenta que escolher. Mostrei aqui 3 opções gratuitas, mas no contexto de trabalho dificilmente algo será grátis. Por isso fica a recomendação geral de evitar fazer SELECT * por aí.
Me diz o que você achou desse tipo de post, e se você gostaria que isso virasse um vídeo no Youtube! Independente do resultado, pra ajudar a decidir sobre o que será o próximo post me acompanha lá no twitter!
Espero que isso tenha sido útil para alguém, até a próxima!



